
Uncertainty-Guided Asymmetric Consistency Domain Adaptation for Histopathological Image Classification

1
Key Laboratory of Autonomous Systems and Networked Control, Ministry of Education, Guangdong Engineering Technology Research Center of Unmanned Aerial Vehicle Systems, South China University of Technology, Guangzhou 510640, China
2
Key Laboratory of Autonomous Systems and Networked Control, Ministry of Education, Guangdong Engineering Technology Research Center of Unmanned Aerial Vehicle Systems, College of Automation Science and Engineering, South China University of Technology, Guangzhou 510640, China
*
Author to whom correspondence should be addressed.
Appl. Sci. 2024, 14(7), 2900; https://doi.org/10.3390/app14072900
Submission received: 3 March 2024
/
Revised: 26 March 2024
/
Accepted: 27 March 2024
/
Published: 29 March 2024
(This article belongs to the Section Computing and Artificial Intelligence)
Abstract
:Deep learning has achieved remarkable progress in medical image analysis, but its effectiveness heavily relies on large-scale and well-annotated datasets. However, assembling a large-scale dataset of annotated histopathological images is challenging due to their unique characteristics, including various image sizes, multiple cancer types, and staining variations. Moreover, strict data privacy in medicine severely restricts data sharing and poses significant challenges in acquiring large-scale and well-annotated histopathological images. To tackle these constraints, Transfer Learning (TL) provides a promising solution by exploiting knowledge from another domain. This study proposes the Uncertainty-guided asymmetric Consistency Domain Adaptation (UCDA), which does not require accessing the source data and is composed of two essential components, e.g., Uncertainty-guided Source-free Transfer Learning (USTL) and Asymmetric Consistency Learning (ACL). In detail, USTL facilitates a secure mapping of the source domain model’s feature space onto the target domain, eliminating the dependency on source domain data to protect data privacy. At the same time, the ACL module measures the symmetry and asymmetry between the source and target domains, bridging the information gap and preserving inter-domain differences among medical images. We comprehensively evaluate the effectiveness of UCDA on three widely recognized and publicly available datasets, namely NCTCRC-HE-100K, PCam, and LC25000. Impressively, our proposed method achieves remarkable performance on accuracy and F1-scores. Additionally, feature visualizations effectively demonstrate the exceptional generalizability and discriminative power of the learned representations. These compelling results underscore the significant potential of UCDA in driving the advancement of deep learning techniques within the realm of histopathological image analysis.
1. Introduction
Histopathology, as an indispensable component of cancer diagnosis, holds immense significance in medical science [1,2]. This field leverages the microscopic examination of tissue samples to identify and classify various forms of cancer, providing a detailed understanding of tumor biology that is critical for accurate diagnosis and treatment planning. Currently, histopathological biopsy remains the primary method for diagnosing benign and malignant tumors [3,4]. The evaluation of histopathology by highly skilled pathologists serves as the gold standard for cancer diagnosis [5]. However, this process often involves repetitive examination and analysis of histopathological images by experienced physicians, which is both demanding and prone to interobserver variations, leading to reduced diagnostic accuracy. Therefore, highlighting the complexity and the critical role of histopathological analysis in cancer care underscores the urgent need for an effective classification and screening approach to facilitate optimal treatment decisions.
The utilization of deep learning techniques in medical image analysis presents a promising perspective to address this demand [6,7]. However, it is crucial to recognize that deep learning models heavily rely on an extensive and accurately annotated dataset, a prerequisite that poses a significant challenge in the dynamic and complex field of histopathological image analysis. The annotation of histopathological image slices, confronted with considerable morphological variability, demands the meticulous effort of expert clinicians, thus contributing to the labor-intensive and costly nature of the task [8,9]. Consequently, acquiring a substantial quantity of accurately labeled data can be a time-consuming and challenging endeavor. In this context, transfer learning emerges as a strategic approach to mitigate these challenges, offering a pathway to enhance the utilization of available labeled data and leverage the vast reservoir of unlabeled histopathological images. This integration into diverse strategies underscores the adaptability and potential of transfer learning to revolutionize histopathological image analysis by optimizing data use and improving diagnostic accuracy.
Transfer Learning (TL), by facilitating the effective knowledge transfer from labeled to unlabeled data, stands at the forefront of innovating medical image classification tasks, particularly in histopathology where the scarcity of labeled data is a prominent issue. Recent studies have explored various transfer learning approaches to leverage unlabeled data and address the limitations of acquiring labeled target data [10,11,12]. For instance, Shi et al. [10] proposed a semi-supervised deep transfer learning framework for benign-malignant pulmonary nodule diagnosis by adopting a pre-trained classification network and leveraging available dataset in the network semantic representation space; Feng et al. [11] designed a contrastive domain adaptation with consistency match approach for saving labeled chest X-ray in training pneumonia diagnosis models; Fang et al. [12] explored a discrepancy-based unsupervised cross-domain fMRI adaptation framework for cross-site major depressive disorder identification, by involving attention-guided graph convolution among labeled source and unlabeled target samples. These examples illustrate the innovative potential of transfer learning to bridge the gap between the available data and the analytical capabilities required for precise histopathological diagnosis, highlighting its transformative impact on the field.
These studies extract valuable knowledge from openly accessible source domain-labeled data, thereby reducing the annotation cost in the target domain. This solution has played a significant role in advancing cross-domain medical image analysis by leveraging existing labeled data resources for knowledge transfer. However, in medical imaging, obtaining labeled source domain data for transfer learning is often challenging due to privacy concerns and data management regulations. Because of this hardship, efficiently using available pre-trained models through source-free approaches like our UCDA is a desirable alternative. Because medical image data largely originates from hospital databases, there are limitations in openly sharing the datasets used, which can pose challenges for certain high-performance methods. However, an alternative solution, known as source-free domain adaptation, has emerged by capitalizing on the use of pre-trained models rather than directly accessing the sensitive source data and the Uncertainty-guided Asymmetric Consistency Domain Adaptation (UCDA) method that we propose further builds on this framework, augmenting it with innovation that explicitly accounts for inconsistencies and missed representations inherent in previous approaches.
Several prior studies have demonstrated the efficacy of source-free domain adaptation (SFDA) in medical image processing [13,14,15]. Specifically, these investigations have primarily focused on medical image segmentation and have yielded promising experimental outcomes, demonstrating the potential of source-free domain adaptation in medical image analysis. However, there is a dearth of research regarding the application of source-free methods in medical image classification, predominantly due to the pronounced uncertainties associated with disease representations in medical images when compared to natural image classification tasks. Moreover, existing methods fail to account for the issue of weak model generalizability resulting from data inconsistency across devices and other factors [16]. Additionally, it is necessary to address the problem of decreasing pseudo-label quality caused by network uncertainty stemming from source models. To solve these obstacles, this work enables knowledge transfer between domains while respecting data privacy and confidentiality restrictions, ultimately circumventing the need for sharing the actual datasets. Through source-free domain adaptation, we can leverage the learned representations and patterns encoded within pre-trained source models to effectively analyze target domains without compromising data security or violating legal and ethical considerations.
In detail, our study presents Uncertainty-guided Asymmetric Consistency Domain Adaptation (UCDA), a novel method enhancing medical image classification without source data access. UCDA integrates Uncertainty-guided Source-free Transfer Learning (USTL) and Asymmetric Consistency Learning (ACL). USTL ensures secure knowledge transfer, preserving data privacy and effectively addressing network uncertainties, while ACL extracts asymmetric features to align the source and target domain feature spaces (Figure 1). This approach significantly improves classification accuracy and robustness, demonstrating UCDA’s potential in advancing medical image analysis with remarkable performance across diverse datasets.
In summary, this study presents the following contributions:
- (1)
- In our research, we present an innovative, source-free transfer learning methodology referred to as Uncertainty-guided Asymmetric Consistency Domain Adaptation (UCDA) designed for the classification of histopathological images. UCDA sets itself apart from typical methods by eliminating the requirement for original source data, therefore maintaining data confidentiality in clinical medical situations. The adaptation of the domain is realized via the distillation of knowledge from a pre-existing source model.
- (2)
- To tackle the uncertainty issues prevalent in medical image classification, we unveil a source-free knowledge distillation mechanism called Uncertainty-guided Source-free Transfer Learning (USTL). This mechanism employs a strategy guided by uncertainty to aid in the correlation of features between the source model and the target data, thereby augmenting the efficiency of knowledge transfer.
- (3)
- We formulate an Asymmetric Consistency Learning (ACL) procedure to evaluate the symmetry and asymmetry across various domains. By instructing the model to connect the domain disparity while keeping the inter-domain variances among medical images, ACL permits feature acquisition from medical images at both symmetric and asymmetric degrees.
- (4)
- To authenticate the efficacy of UCDA, we execute comprehensive experiments on three public datasets. The findings from the experiments reinforce the efficiency of our model in analyzing medical images, elucidating its potential applicability in tasks relating to histopathological image classification.
2. Related Work
In this section, we begin by providing a comprehensive overview of recent advancements in medical image classification utilizing supervised learning techniques. Subsequently, we explore the application of domain adaptation in medical image classification through an analysis of recent studies in the field.
2.1. Medical Image Classification Based on Supervised Learning
In recent years, the field of deep learning has experienced significant advancements, leading to remarkable medical applications for addressing classification problems. Within the medical imaging domain, numerous outstanding studies have emerged, demonstrating the efficacy of supervised learning in developing high-performance models [17,18,19]. For instance, Xue et al. [17] introduced a cooperative training paradigm encompassing both global and local representation learning for medical image classification. Placido et al. [18] leveraged deep learning methods on clinical data obtained from the Danish National Patient Registry (DNPR) comprising 6 million patients (including 24,000 pancreatic cancer cases), as well as data from the United States Veterans Affairs (US-VA) involving 3 million patients (including 3900 cases). Their findings exhibited improved capabilities in designing realistic surveillance programs for high-risk patients. Furthermore, Jiang et al. [19] integrated deep learning techniques into MRI analysis to predict survival outcomes in patients with rectal cancer, utilizing segmented tumor volumes extracted from pre-treatment T2-weighted MRI scans. These studies serve as compelling examples of the successful application of deep learning and supervised learning approaches in various medical image classification tasks, highlighting promising advancements and potential avenues for future research.
In supervised medical image classification, feature fusion has emerged as a pivotal factor in enhancing the performance of medical image classification in recent years. Notably, Rehman et al. [20] leveraged neural network principles, streamlined feature vectors, and a variety of machine learning techniques to distinguish between mitotic and non-mitotic cells in breast cancer histology images. Their approach assigns differential weights to various features, thereby boosting the model’s efficiency. Similarly, Huo et al. [21] introduced a novel three-branch hierarchical multi-scale feature fusion network architecture tailored for medical image classification. This model underscores the significance of integrating both global and local multi-scale features, affirming its critical role in the domain of medical image classification.
It should be emphasized that supervised learning approaches are significantly dependent on extensive labeled datasets, a dependency that necessitates resource-intensive and costly efforts. This typically involves the manual annotation of data by domain experts. In the realm of medical imaging, the acquisition of labeled datasets is further complicated by privacy considerations, culminating in a scarcity of publicly available labeled medical datasets.
2.2. Domain Adaptation in Medical Image Analysis
To address the issue of requiring a large amount of expertly annotated data for supervised learning models, domain adaptation can leverage knowledge from existing annotated datasets to jointly train medical image classification models on target unlabeled samples. This approach circumvents the need for extensive annotation efforts on target domain medical image data. In recent years, numerous domain adaptation-based medical image classification methods have been proposed, significantly advancing research progress in this specialized field [22,23,24]. For instance, Zhang et al. [22] proposed a multi-modality transfer learning network with a hybrid bilateral encoder for hypopharyngeal cancer segmentation. Their method effectively transfers prior experience from large computer vision datasets to multi-modality medical imaging datasets. Wen et al. [23] integrated multi-level progressive transfer learning to exploit knowledge acquired from rectum cancer (source domain) to cervical cancer (target domain) for dose map prediction tasks. Wang et al. [24] introduced a deep transferred semi-supervised domain adaptation model, achieving robust histopathological whole slide image classification results even with limited labeled samples. These studies highlight the successful application of domain adaptation techniques in various medical imaging tasks, demonstrating their potential for improving classification performance and expanding the scope of medical image analysis.
Taking into account the aforementioned statements, existing domain adaptation methods for medical image analysis typically require full access to the source data. However, due to privacy requirements and strict data protection regulations, accessing the source domain data is often infeasible. Conversely, source pre-trained models are publicly available to the target model. Therefore, this paper focuses on investigating domain adaptation methods that solely rely on accessing the pre-trained source models, specifically for training medical image classification models in the target domain.
2.3. Uncertainty-Based Transfer Learning Technology
In the realm of transfer learning, the uncertainty inherent in feature representations poses substantial challenges to the stability and robustness of general image classification models. Recent advancements in uncertainty-aware transfer learning seek to navigate these challenges by leveraging uncertainty to enhance model performance. Notably, Hu et al. [25] explored the intricacies of transferability estimation within domain adaptation, introducing a non-intrusive method for unbiased transferability estimation. This approach utilizes uncertainty modeling within adversarial domain adaptation frameworks to refine the optimization process. Similarly, Pei et al. [26] introduced an innovative uncertainty-induced methodology for assessing transferability. This technique employs uncertainty as a means to evaluate the channel-wise transferability of features from the source encoder in scenarios where source data and target labels are unavailable.
Furthermore, the integration of uncertainty into transfer learning has seen promising applications within medical image analysis for clinical use cases. Shamsi et al. [27] developed a deep uncertainty-aware transfer learning framework tailored for COVID-19 detection, employing convolutional neural networks (CNNs) to extract features from chest X-ray and computed tomography images. This framework incorporates epistemic uncertainty to identify regions of low confidence in the model’s predictions. Moreover, Ebadi et al. [28] crafted a deep learning architecture for the sequential analysis of cancer tumor progression using Cone Beam Computed Tomography (CBCT) images. This model incorporates an attention mechanism and provides uncertainty estimates for segmentation tasks, contributing to risk management in treatment planning and enhancing the model’s calibration and reliability.
Drawing inspiration from these pioneering works, our study introduces an uncertainty-guided source-free transfer learning approach. This model capitalizes on an uncertainty-guided mechanism to enable effective feature mapping from the source model to target data, thereby facilitating knowledge transfer in source-free domain adaptation tasks for medical image classification. Compared to the aforementioned works, this approach underscores the potential of integrating uncertainty into transfer learning frameworks to solve inter- and intra-domain imbalances. It progressively approximates the feature space of the target and source model’s distributions through various inter- and intra-domain alignment strategies, improving adaptability and efficacy in domain adaptation scenarios.
3. Method
To release supervised learning from labeled medical images and protect data privacy, this paper proposes a novel source-free domain adaptation framework for medical image classification, namely Uncertainty-guided asymmetric Consistency Domain Adaptation (UCDA), to learn representative features from histopathological images by solving the challenges caused by the uncertainties and inter-domain discrepancy.
The Uncertainty-guided Asymmetric Consistency Domain Adaptation (UCDA) framework, illustrated in Figure 2, integrates two core modules: Uncertainty-guided Source-free Transfer Learning (USTL) and Asymmetric Consistency Learning (ACL) for optimizing histopathological image classification. USTL pioneers in facilitating secure knowledge transfer from source domain models to the target domain without direct access to source data, thereby maintaining utmost data privacy. This module quantifies and mitigates network uncertainties, generating high-quality pseudo-labels through the identification of shared characteristics between source and target domains. Subsequently, the ACL module is instrumental in identifying and leveraging asymmetric features across samples, crucial for effectively aligning the source model’s feature space with the target domain. This process not only enhances classification accuracy and robustness but also navigates the challenges posed by the absence of source data. Moreover, ACL’s focus on inter-domain asymmetry fosters a comprehensive alignment of feature spaces, ensuring a refined and secure adaptation process. Collectively, UCDA’s innovative approach underscores its efficiency and the potential for advancing deep learning applications in medical image analysis, demonstrating significant improvements in accuracy and model generalizability.
3.1. Preliminaries
For the cross-domain histopathological image classification task, we define the datasets for the source and target domains as and , respectively. The corresponding labels for the source and target domains are defined as and , where and represent the number of medical images. Notably, the labels in the target domain, denoted as , are treated as pseudo-labels. Assuming that the model for the UCDA source domain is denoted as , and the model for the target domain is denoted as . The training process involves initializing the network parameters of model with the completed training of model . During the training of the target domain model, the network parameters of the source domain model are frozen to simulate a scenario without access to the source domain data.
In the process of our source-free domain adaptation, two main steps are typically involved. The first step entails training the source domain model, where the network parameters are updated through cross-entropy. In the second step, the focus shifts to maximizing the mutual information between the potential features and the classifier output.
First, the cross-entropy loss function for the pre-trained Source Classification (SC) model is defined as
where is the network parameters of source classification model .
In the second step, the source data is deactivated, and the network parameters of the target domain model are initialized using the parameters of . Subsequently, an information maximization loss is employed to update the network parameters of .
where is a given target sample, denotes the predicted probability vector of , C represents the category number of medical images, and refers to the possibility of c-th representation in the output of the target domain model. Specifically, is responsible for updating the pseudo-labels for the target domain, while is used to classify the model predictions into C classes.
In addition, due to the inherent differences in data and models between the source and target domains, aligning the two domains in the absence of source domain data becomes even more challenging. The fixed source domain model leads to overconfident predictions, disregarding the discrepancies between domains and resulting in erroneous mappings of target domain data. To address this, we propose incorporating the uncertainty of neural network weights into the model predictions. This requires treating the model parameters W in a Bayesian framework, where the posterior distribution of model parameters is obtained by adjusting the data X, i.e., . The prediction of the network for an observation x is given by the predictive posterior distribution, i.e.,
where is the probability belonging to c-th class. It is important to mention that the posterior in Equation (4) generally lacks a direct analytical solution and therefore requires approximation. In order to facilitate this, we engage a local approximation technique for the posterior. Specifically, we utilize the Laplace Approximation (LA) [29] for dealing with the model’s uncertainty about weight parameters. Laplace Approximation (LA), a simple yet effective method for approximate Bayesian inference, approximates the posterior distribution of these parameters, thereby embodying the model’s uncertainty over them and their impact on the predictions. LA estimates the actual posterior through the implementation of a multivariate Gaussian distribution, which is centered around a locally optimal point, and utilizes a covariance matrix derived from the inverse of the negative log posterior’s Hessian . Meaning, where . Here, signifies the maximum a posteriori probability (MAP) estimate of the parameters of the network.
However, this technique has its potential limitations. Laplace approximation demands computing the inverse of the Hessian Matrix—used to comprehend the curvature characteristics of the distribution—implying computational difficulties and enhancing the associated computational cost when dealing with larger networks. Another significant factor would be requiring determining a point around which the approximation is to be set up; this is generally the mode (maximum) of the distribution, which can also be complex to compute for larger configurations. Since some large networks have a huge number of parameters, which makes calculating H very difficult, we also made another simplification by applying a Bayesian treatment only to hypothesis function , known as the last-layer Laplace approximation.
In this part, h denotes the potential representation of the target domain model. Although the last-layer LA significantly reduces the computational load for larger networks, calculating the Hessian can present challenges when the class count is high. To streamline computations, we hypothesize that can be Kronecker-factored as . The ensuing approximation is known as the Kronecker-factored Laplace approximation.
Subsequently, we utilize the estimates of uncertainty for target adaptation through the implementation of Monte Carlo (MC) integration. The approximate predictive posterior distributions are as follows:
Here, M stands for the total count of MC steps. To foster predictions with low entropy, we further scale the hypothesis outputs by a factor of , where . Eventually, the definitive weight of each observation is calculated as , with ‘e’ representing the entropy of the predictive mean.
3.2. Uncertainty-Guided Source-Free Transfer Learning
In a typical transfer learning training task, there exists a divergence in data distribution and content between the source and target domain datasets, resulting in imbalances both inter- and intra-domain. This lack of alignment is referred to as “unalignment”. However, by adapting the source domain data, we can progressively approximate the feature space of the target and source domain models through various inter- and intra-domain alignment strategies. Nevertheless, this task becomes more challenging in the case of source-free domain adaptation since the source data are inaccessible in this scenario.
In this paper, we directly leverage the pre-trained source model to transfer knowledge to the target domain. However, a significant challenge arises when using the source model to generate pseudo-labels for target data, as it may result in uncertain predictions. To address this uncertainty issue, we propose an uncertainty-guided transfer learning strategy, which can quantitatively estimate the uncertainty of the source domain model to prevent reduced accuracy caused by overconfidence in the pseudo-labeling process.
First, we conduct a complete pre-training session by feeding the source domain data into model . This simulation is performed to establish the source domain model, which will remain unchanged in subsequent tasks. During this training session, the parameters of the source network are updated by minimizing the source loss .
where represents the source network parameters of . Through the aforementioned update approach, the network parameters are adjusted, enabling the source domain network to effectively extract features and recognize patterns from the source domain data. In other words, the source domain model gains the capability to capture specific lesion characteristics from medical images within the source domain. This serves as a crucial foundation for our subsequent unsupervised domain adaptation tasks, even in the absence of source domain data.
To evaluate the uncertainty in the subsequent target domain training task, we employ the Laplace approximation method to estimate the posterior distribution of the predicted values. This approach is described in Equation (5) in the preliminary section.
With the completion of the aforementioned steps, we are prepared for the subsequent tasks. Prior to commencing the training of the target model, we initialize using the frozen network parameters of . This initialization ensures that the target model starts with the knowledge transferred from the source domain model.
where denotes the parameters of the target network, and is the generated pseudo-label for the target data.
As for the pseudo-labeling process in the target domain, we apply a filtering mechanism by ranking the predicted probabilities. Specifically, for the first ten epochs, both the probability predicted from source model and the one from target model must exceed the probability threshold in order to pass the screening for pseudo-labels.
3.3. Asymmetric Consisteny Learning
Transfer learning between the source model and target data requires addressing both inter-domain feature differences and intra-domain feature biases, which result in an asymmetric feature mapping from the source to the target domain. Consequently, the focus of this paper includes investigating asymmetric feature learning. To accomplish this, we propose an Asymmetric Consistency Learning module that facilitates the successful asymmetric mapping of the feature space from the source domain into the target domain. This module enables more accurate knowledge transfer for medical image analysis.
Continuing from the previous section, we proceed with the basic network training using the pseudo-labels generated and unlabeled data obtained from the target dataset. This training process is carried out to minimize the following loss :
where represents the parameters of the target network.
This training process extends over several epochs, allowing the target domain model to rapidly acquire feature extraction capabilities. Essentially, this process can be viewed as a form of fine-tuning, wherein the target domain model, initialized with parameters from the source domain model, undergoes domain-specific alignment. This alignment enables the target domain network to emphasize the lesion characteristics present in the target domain data, leveraging the knowledge and representations acquired from the source domain network.
Next, we introduce the Asymmetric Consistency Learning (ACL) mechanism to align the target domain in an asymmetric manner from the source domain, without relying on the assistance of source data. The asymmetric consistent similarity between and is calculated by,
where represents the cosine similarity. By utilizing this approach, we obtain a quantifiable measure of asymmetric dissimilarity between the feature spaces of the source and target models. This forms the fundamental principle for establishing an asymmetric consistency in our framework.
With the similarity computed as described above and utilizing the approximation strategy mentioned in Equation (6) in the preliminary section, we derive the asymmetric consistency loss and uncertainty-guided adaptation loss as follows.
where is the set of samples in and denotes those examples that are farther away from a than x in . denotes the anchor sample a, which is randomly selected from the training batch, to formulate the set . For , denotes the output probability belonging to c-th class.
In this way, enables inter-domain alignment between the target and source domains, while ensures a safer and more precise strategy for intra-domain alignment within the target domain. As a result, the target domain network retains its understanding of lesion features from the source domain data, while also learning lesion features specific to the target domain. This dual learning process guarantees optimal model performance by effectively harnessing knowledge from both domains.
To further optimize , we devise a contrastive loss and ensure in the following way:
where y is the label indicating whether the two samples in match or not. The variable l denotes the Euclidean distance between two samples, and m signifies the distance threshold.
Finally, the overall loss function in target domain adaptation is shown below,
where , , and are the balance parameters. As a conclusion, the network training steps are summarized in Algorithm 1.
| Algorithm 1 The training steps of UCDA |
1:Input: The pre-trained source model from and , the target data 2:initial: The pre-trained source model , and the target model . Repeat: Send the images to ; Generate the pseudo-labels for this batch via Equation (9); Update the parameters of the target model via Equation (15); Calculate the similarity between asymmetric samples via Equation (11); Update the parameters of via Equation (15); Until Convergence; Output The target model . |
4. Experiments
4.1. Database Description
To evaluate the effectiveness of our UCDA approach in source-free medical image classification, we conducted experiments using three publicly available histopathological image datasets: NCT-CRC-HE-100K [30], PCam [31], and LC25000 [32].
The NCT-CRC-HE-100K dataset [30] includes 100,000 unique image patches from 86 HE-stained human cancer tissue slides and normal tissue samples derived from the NCT biobank (National Center for Tumor Diseases) and the UMM pathology archive (University Medical Center Mannheim). The dataset is meticulously categorized into nine distinct tissue classes by expert pathologists.
In contrast, the PCam dataset [31] has 327,680 color images (96 × 96 px) from histopathologic scans of lymph node sections, each labeled for the manifestation of metastatic tissue. Originating from the Camelyon16 Challenge [33], PCam provides a benchmark for machine learning models, offering a dataset size larger than CIFAR10 but smaller than ImageNet, hence trainable on a single GPU.
Finally, the LC25000 dataset [32] houses 25,000 histopathological images classified into five different classes; for our specific objectives, we selected a subset of 15,000 images related to lung pathology, including lung adenocarcinoma, lung squamous cell carcinoma, and benign lung tissue.
4.2. Implementation Details
Parameter Settings: The experiments for UCDA were conducted on two Nvidia GeForce 3090 GPUs using the PyTorch 1.8 framework. The ResNet50 architecture was used as the backbone network, and all networks were initialized with pre-trained models from ImageNet. The datasets were augmented with random flips, cropping, and rotations. To evaluate the effectiveness of our UCDA method, we first performed basic training on the source domain to simulate the scenario where no source domain data are available for subsequent adaptation. Before inputting medical images into the network, preprocessing was applied, and all images were scaled to dimensions of 512 × 512 pixels. During the training of UCDA, we employed the Adam optimizer with a learning rate of 10−3 with weight decay 10−4. The training process spanned a total of 100 epochs, with a batch size set to 32. The classifier consisted of multiple linear layers, and the balancing coefficients are set as , , and , where the threshold parameter is .
Training Steps: In model training, UCDA first utilized the uncertainty of the source domain model to select high-confidence samples from the network’s predictions, combining them with the target domain model, and then the model was trained by optimizing the loss function in the target domain. In order to demonstrate the capability of our UCDA in medical image analysis, we incorporate labeled target images with varying ratios to fine tune the network. This process aims to enhance the semi-supervised performance of the source-free domain adaptation.
Data Division: To perform transfer learning, we employ the NCT-CRC-HE-100K dataset as the source domain for pre-training a medical image classification model. This pre-trained model is then utilized for source-free domain adaptation on the other two histopathology datasets. For each target domain, we start by replacing the prediction layer with the corresponding class number specific to that dataset, to create the UCDA model. Moreover, sufficient validations are also conducted in the following discussion. Regarding the target domains, we incorporated the PCam dataset and LC25000 datasets for lung cancer diagnosis. Specifically, the PCam dataset was utilized to detect the presence of metastatic tissue, while 15,000 images from the LC25000 dataset were employed to identify lung pathology related to lung adenocarcinoma, lung squamous cell carcinoma, and benign lung tissue. Taking NCT-CRC-HE-100K as the target domain, we utilize the PCam dataset as a source to conduct the source-free domain adaptation, where the experimental setting is similar to that previously mentioned.
Evaluation: The performance of the proposed UCDA method and the compared methods is evaluated using accuracy and macro F1-score on the testing set. Additionally, the Receiver Operating Characteristic (AUC) curve, t-Distributed Stochastic Neighbor Embedding (t-SNE), and loss curves visualization are utilized to demonstrate the classification capability of the UCDA model. Furthermore, ablation studies are conducted to assess the effectiveness of the major components of UCDA.
4.3. Experimental Results
To thoroughly assess the effectiveness of our UCDA approach, we conducted validation experiments on the PCam and LC25000 datasets using transfer learning from the NCT-CRC-HE-100K pre-trained model. To establish a comprehensive comparison, we also incorporated three state-of-the-art unsupervised methods, namely Rotation [34], DeepCluster [35], and DARC [36], which employ fine-tuning on the labeled data.
As presented in Table 1, the experimental results report the performance of our UCDA approach in various labeled data ratios. Given 1% labeled data, the UCDA method demonstrates higher accuracy and F1 scores compared to Rotation, DeepCluster, and DARC. The UCDA method achieves an accuracy of 86.83% (PCam) and 90.91% (LC25000), with corresponding F1 scores of 86.60% (PCam) and 90.89% (LC25000); At a 10% labeled data ratio, the UCDA method continues to exhibit superior performance. It achieves an accuracy of 88.65% (PCam) and 96.59% (LC25000), with F1 scores of 88.68% (PCam) and 96.52% (LC25000). Compared to other methods, while the UCDA method’s accuracy on LC25000 is slightly lower than DARC and DeepCluster, it still outperforms Rotation; At a 50% labeled data ratio, the UCDA method achieves high accuracy and F1 scores on both PCam and LC25000. Its accuracy reaches 89.78% (PCam) and 96.36% (LC25000), with corresponding F1 scores of 89.63% (PCam) and 96.30% (LC25000). It is worth noting that although the UCDA method’s accuracy on LC25000 is slightly lower than DARC, it remains superior to them on PCam. As for the NCT-CRC-HE-100K dataset, our UCDA obtains significant advantages compared to DeeCluster [35] and DARC [36], where it surpasses DARC with 2.03% accuracy and 2.09% F1-score on 1% labeled data. These results verify that the proposed UCDA has obvious superiority compared to existing methods in the source-free domain adaptation models.
To summarize, the UCDA method demonstrates high performance at different labeled data ratios, providing better classification accuracy than other methods. These results highlight the potential and effectiveness of the UCDA method in the field of medical image analysis, offering strong support for further research and applications.
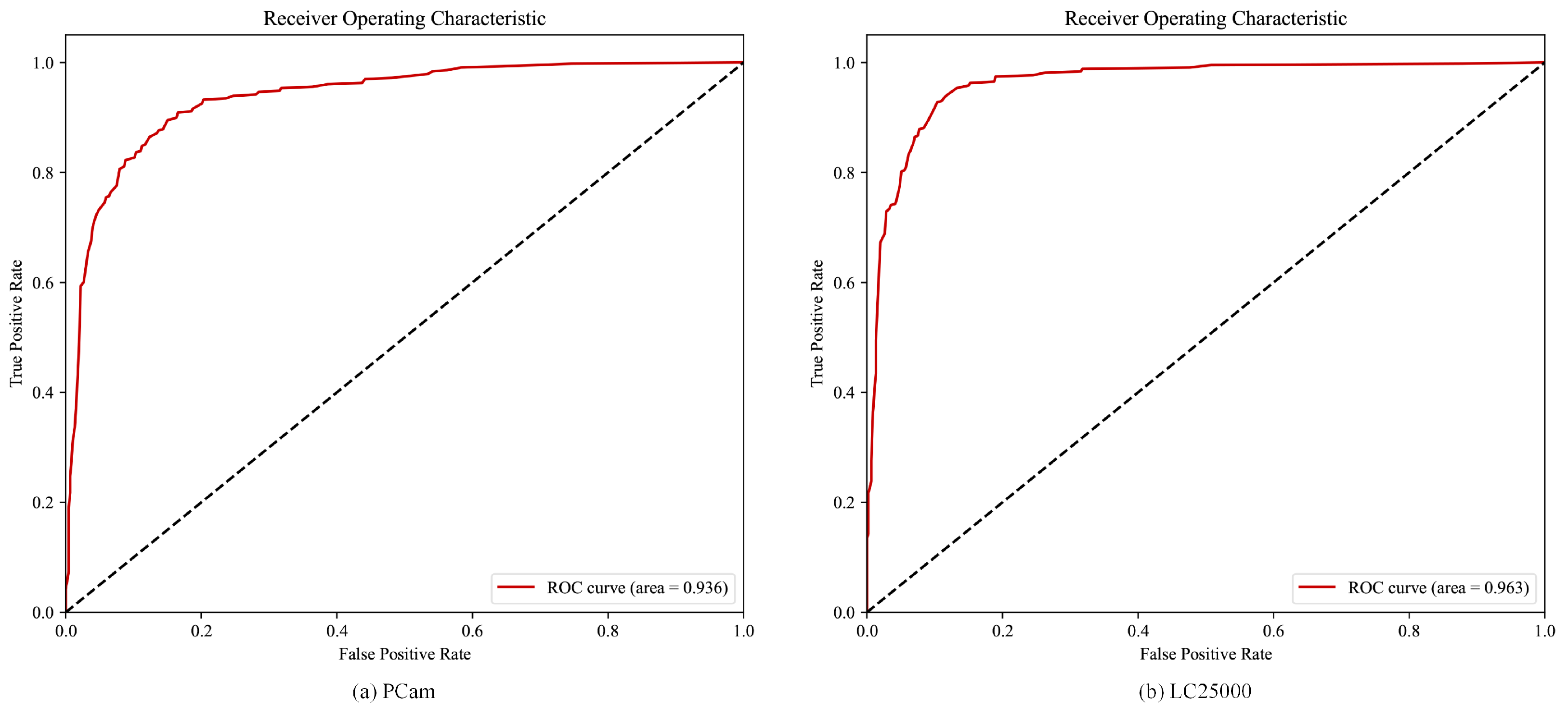
The ROC Performance of UCDA
To assess the effectiveness of the UCDA method in medical image classification, we conducted ROC curve analysis on the PCam and LC25000 datasets with 1% labeled data. The corresponding ROC curves are presented in Figure 3a,b. ROC curves are widely used in signal detection theory for evaluating classification systems, providing valuable insights into their performance.
ROC analysis enables us to make objective and unbiased decisions, irrespective of costs or benefits. It allows us to visualize the trade-off between sensitivity (true positive rate) and specificity (1—false positive rate) at different decision thresholds, thereby assessing the discriminatory power of the UCDA method under various scenarios.
As depicted in Figure 3a,b, the ROC curves for the PCam and LC25000 datasets exhibit AUC values of 0.936 and 0.963, respectively. These results indicate that the UCDA method demonstrates excellent performance in medical image classification tasks on these datasets. Moreover, the AUC values exceeding 0.9 further reinforce the superiority, robustness, and generalization capability of the proposed UCDA method.
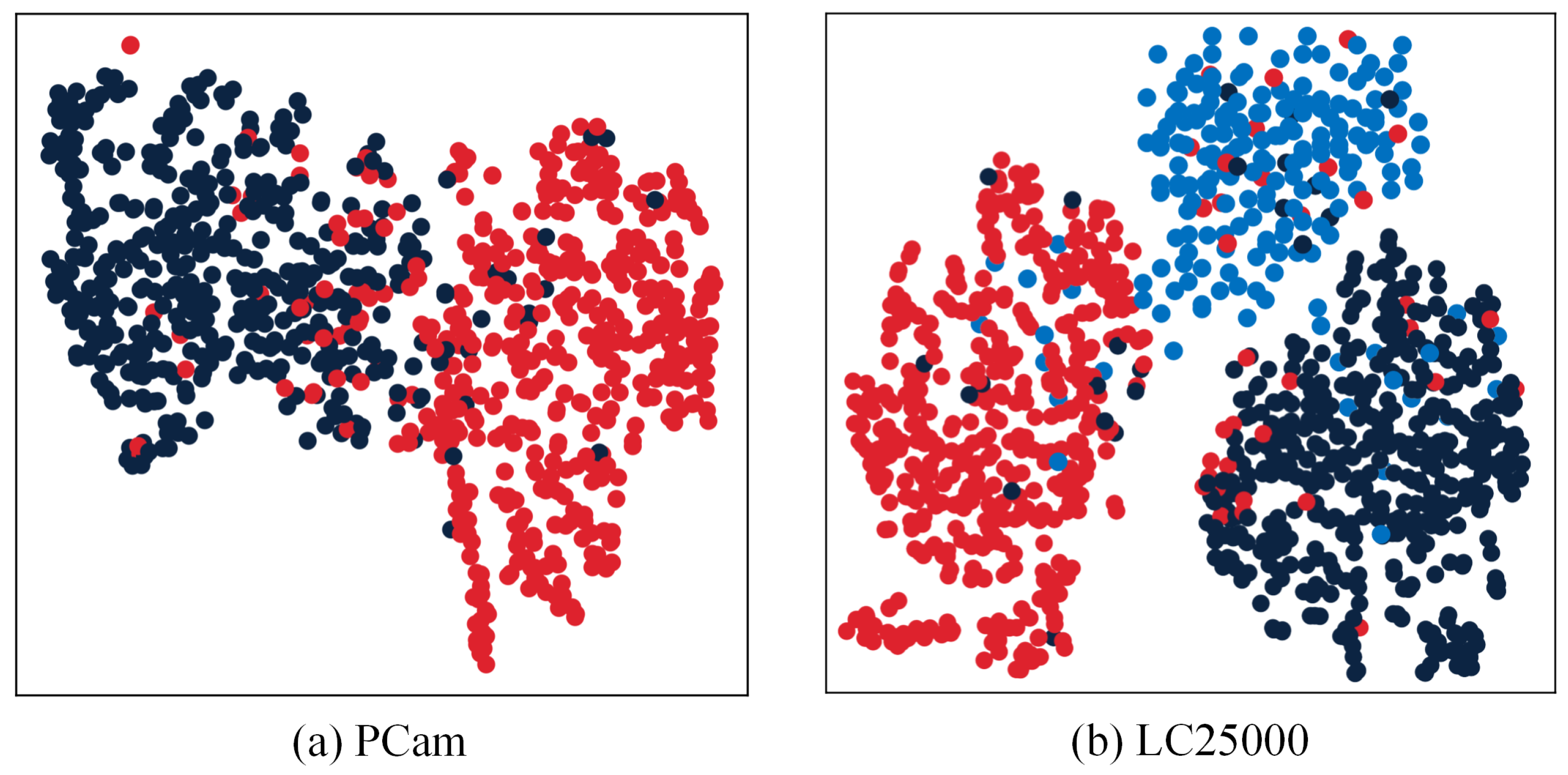
4.4. Visualization of the Learned Representations
In addition to evaluating UCDA’s performance using ROC curves, we conducted further analysis of the datasets. This involved generating t-distributed Stochastic Neighbor Embedding (t-SNE) visualizations to explore the extracted features. t-SNE is a widely used data visualization technique for dimensionality reduction, facilitating the intuitive representation of high-dimensional data and revealing its distribution.
As illustrated in Figure 4, the t-SNE visualizations on PCam and LC25000 exhibit distinct separation of features extracted by the UCDA network into distinctive classes. This observation provides evidence that UCDA effectively captures discriminative information from medical images, resulting in improved classification accuracy of the model. The visualizations serve as compelling evidence of UCDA’s efficacy in enhancing the model’s performance for medical image classification tasks. They underscore UCDA’s ability to accurately discriminate between different classes with a high level of precision.
4.5. Performance with Different Backbone Networks
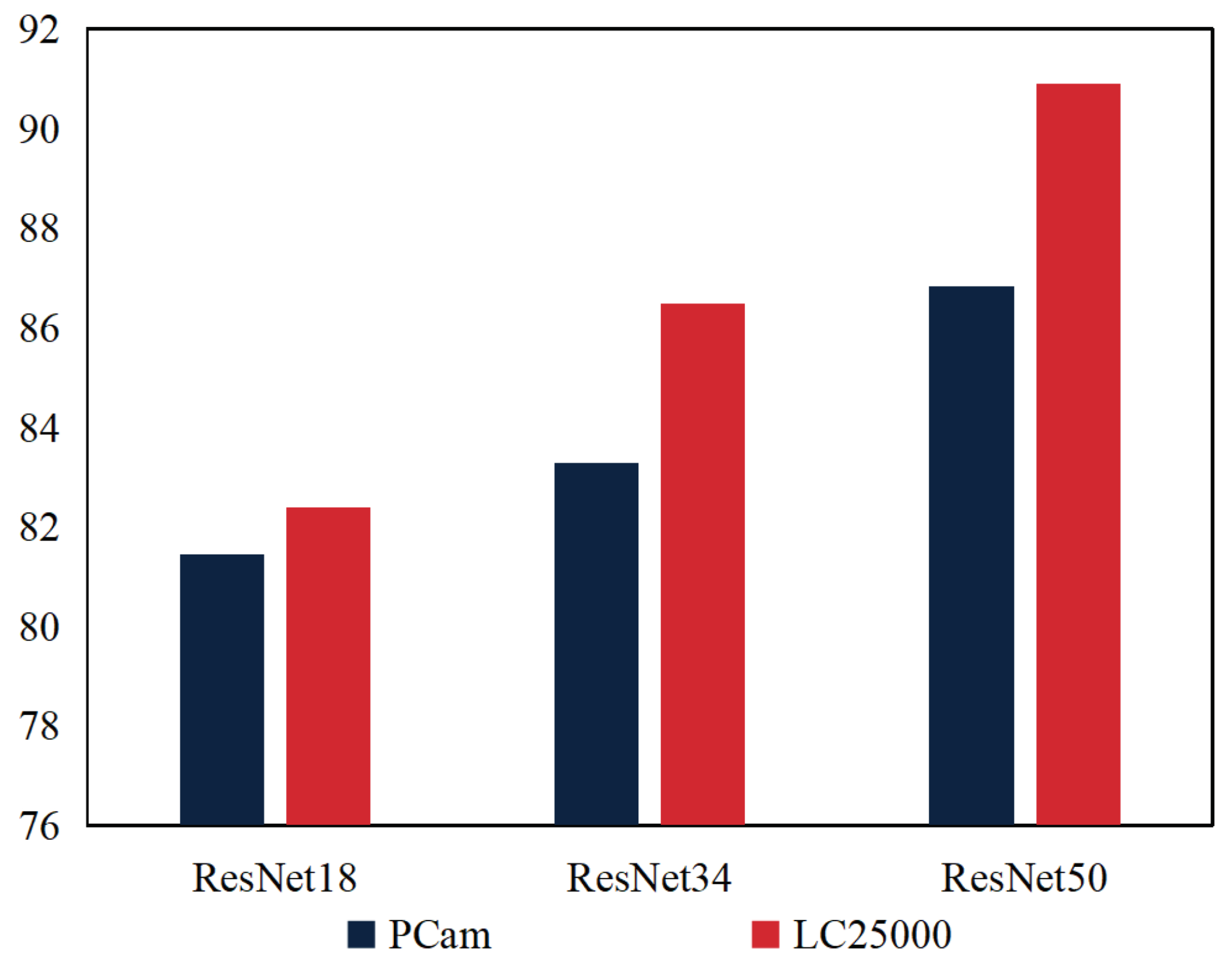
To further validate our UCDA method, we conducted extensive experiments to implement UCDA using different backbone networks, namely ResNet18, ResNet34, and ResNet50, giving 1% labeled target data on the PCam dataset. The results, as illustrated in Figure 5, affirm that all variants of UCDA with diverse backbones achieve satisfactory classification performance throughout model training.
In Figure 5, the performance of the UCDA model on different backbone networks is analyzed based on the provided medical images. The results indicate that as the complexity of the backbone network increases, the UCDA model achieves higher accuracy on both the PCam and LC25000 datasets. Specifically, when using the ResNet18 backbone network, the UCDA model achieves 81.4% accuracy on the PCam dataset and 82.3% accuracy on the LC25000 dataset. By utilizing the more complex ResNet34 backbone network, the model’s accuracy improves to 83.3% on PCam and 86.5% on LC25000. Furthermore, employing the deeper ResNet50 backbone network yields even higher accuracy, with the model achieving 86.8% on PCam and 90.9% on LC25000.
These findings suggest that selecting an appropriate backbone network is crucial for improving performance on medical image classification. Notably, the results highlight the advantage of deeper network structures in capturing image features and enhancing classification accuracy. While the choice of backbone network significantly influences the model’s performance, it is important to consider other factors such as data preprocessing, loss function selection, and training strategies. These additional factors should be carefully optimized to further enhance the overall performance of the UCDA model.
4.6. Ablation Study
4.6.1. Effectiveness of the Uncertainty-Guided Adaptation Loss
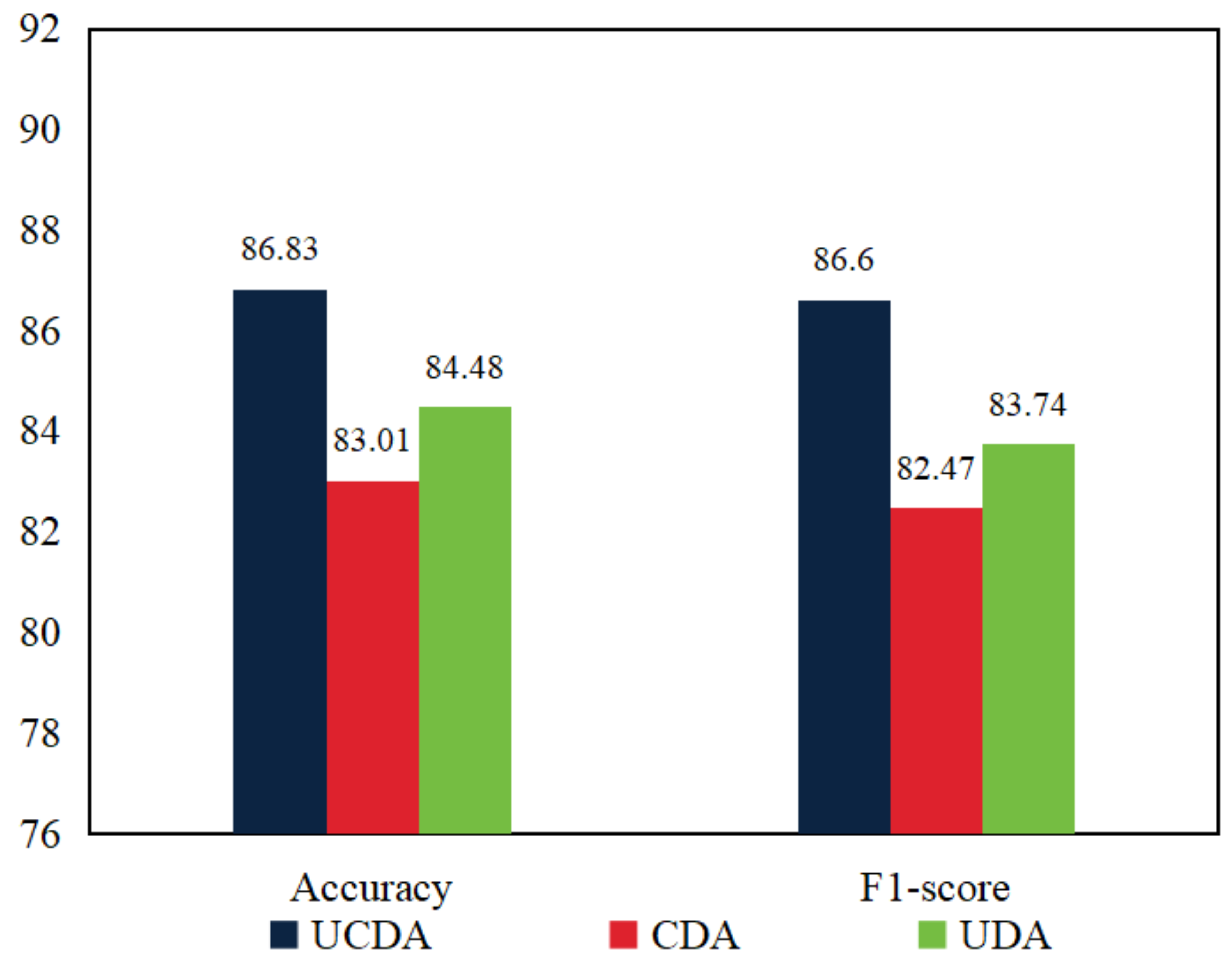
To evaluate the efficacy of the proposed uncertainty loss (), we conducted supplementary experiments where we removed the uncertainty loss and retained only the asymmetric consistency loss for evaluating model performance, referred to as CDA (Figure 6). Specifically, using the PCam dataset with 1% labeled data, we compared the overall performance of UCDA with and without the uncertainty loss.
The outcomes presented in Figure 6 demonstrate that when incorporating the uncertainty loss in the proposed approach, UCDA outperforms the model without the uncertainty loss in terms of accuracy and F1-score, achieving improvements of 3.82% and 4.13%, respectively. These findings validate the effectiveness and indispensability of the uncertainty loss, indicating its ability to enhance the accuracy of pseudo-labels. Consequently, UCDA becomes more cautious in differentiating between lesion features within medical images. The inclusion of the uncertainty loss contributes value by refining model predictions and improving the quality of generated pseudo-labels, which collectively contribute to the overall enhanced performance of UCDA.
4.6.2. Effectiveness of the Asymmetric Consistency Loss
Furthermore, in addition to the performance comparison with the uncertainty loss, we also evaluated the impact of removing the asymmetric consistency loss () on UCDA’s performance, as depicted in Figure 6 (UDA). For this purpose, we conducted additional experiments on the PCam dataset where we excluded the asymmetric consistency loss and analyzed the resultant changes in model performance.
As illustrated in Figure 6, when the asymmetric consistency loss is incorporated into our method, UCDA exhibits superior performance compared to the model without the asymmetric consistency loss. Specifically, UCDA achieves improvements of 2.35% in accuracy and 2.86% in F1-score. These findings validate the effectiveness of the asymmetric consistency loss in promoting domain alignment within UCDA. By leveraging the asymmetric loss, UCDA accurately maps the feature space from the source domain to the target domain, facilitating enhanced alignment between the two domains. Consequently, UCDA demonstrates improved performance in lesion recognition, benefiting from the refined domain alignment achieved through the asymmetric consistency loss.
4.6.3. Parameter Analysis
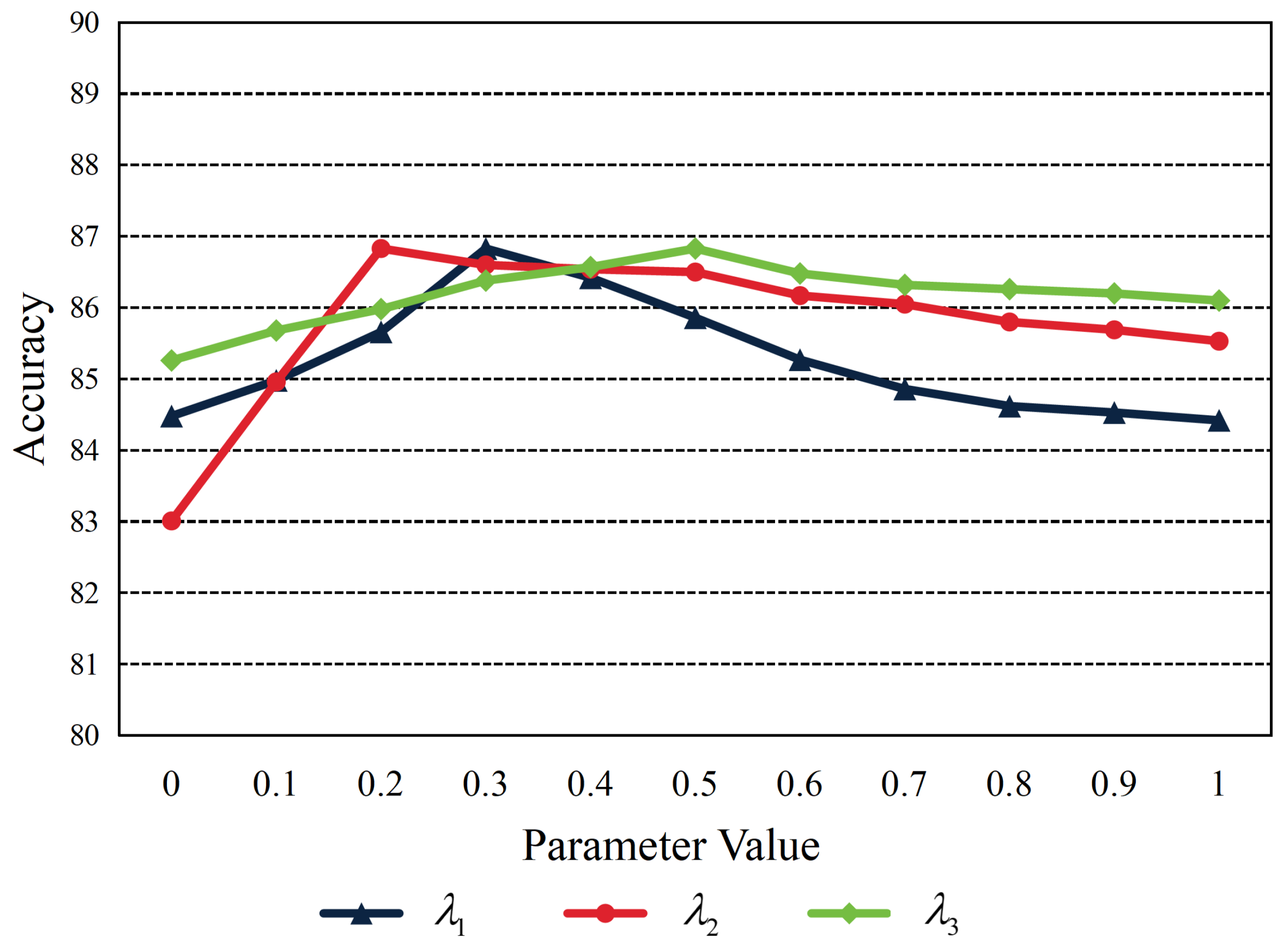
In our UCDA method, the balance parameter of the final loss function (Equation (15)), denoted as , , and , jointly decide the model’s sensitivity toward asymmetric consistency loss , uncertainty-guided adaptation loss , and the contrast loss . Setting the balance parameters appropriately is essential as it assists in directing the learning toward our selected objective. During our experiments, these hyperparameters have undergone exhaustive tuning, which is shown in Figure 7.
It is worth noting that although we have landed on effective configurations for , , and with regard to the PCam dataset, these set values reached optimal accuracies when , , and . Theoretically, the ideal range and values for these parameters will vary according to the distinct characteristics of different data and should be ascertained each time via astute tuning tailored explicitly for specific tasks.
5. Discussion and Conclusions
In this paper, we propose a novel approach called Uncertainty-guided Asymmetric Consistency Domain Adaptation (UCDA) for medical image classification. The UCDA approach leverages the Uncertainty-guided Source-free Transfer Learning (USTL) and Asymmetric Consistency Learning (ACL) modules to enhance domain adaptation performance. The major issue this paper solved is to release the necessity of accessing source data in domain adaptation for medical image classification. The USTL module is introduced as an uncertainty-guided domain adaptation method, enabling effective alignment between the source and target domains. By quantifying the uncertainty of the source domain model, the UA module ensures secure knowledge transfer from the source to the target domain, preventing overconfidence in the network. Furthermore, the ACL module measures the discrepancy between the feature spaces of the source and target models. It incorporates inter-domain and intra-domain metric learning loss functions to improve the performance of the target domain model. Experimental results demonstrate the superiority of the proposed UCDA method compared to baseline methods, achieving better performance while reducing annotation workload. Across three datasets, UCDA consistently outperforms several baseline methods, revealing its potential for medical image classification tasks.
However, it is important to note that UCDA still requires a certain amount of labeled medical images. One limitation of UCDA is that its performance might deteriorate when facing new scenarios with significant distribution differences from previous domains. Therefore, future research will focus on exploring transfer learning and unsupervised learning techniques to further enhance medical image classification performance. By addressing the limitations and continuously advancing the proposed approach, we aim to contribute to the field of medical image analysis and provide valuable insights for real-world applications.
Author Contributions
C.Y.: Methodology, validation, investigation, writing—original draft preparation; H.P.: Supervision, writing—review and editing, project administration, funding acquisition. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by Scientific Instruments Development Program of NSFC [61527810], and the Fundamental Research Funds for the Central Universities.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Shmatko, A.; Ghaffari Laleh, N.; Gerstung, M.; Kather, J.N. Artificial intelligence in histopathology: Enhancing cancer research and clinical oncology. Nat. Cancer 2022, 3, 1026–1038. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Yang, S.; Zhang, J.; Wang, M.; Zhang, J.; Yang, W.; Huang, J.; Han, X. Transformer-based unsupervised contrastive learning for histopathological image classification. Med. Image Anal. 2022, 81, 102559. [Google Scholar] [CrossRef] [PubMed]
- Yang, H.; Kim, J.Y.; Kim, H.; Adhikari, S.P. Guided soft attention network for classification of breast cancer histopathology images. IEEE Trans. Med. Imaging 2019, 39, 1306–1315. [Google Scholar] [CrossRef] [PubMed]
- Hölscher, D.L.; Bouteldja, N.; Joodaki, M.; Russo, M.L.; Lan, Y.C.; Sadr, A.V.; Cheng, M.; Tesar, V.; Stillfried, S.V.; Klinkhammer, B.M.; et al. Next-Generation Morphometry for pathomics-data mining in histopathology. Nat. Commun. 2023, 14, 470. [Google Scholar] [CrossRef] [PubMed]
- Davri, A.; Birbas, E.; Kanavos, T.; Ntritsos, G.; Giannakeas, N.; Tzallas, A.T.; Batistatou, A. Deep Learning on Histopathological Images for Colorectal Cancer Diagnosis: A Systematic Review. Diagnostics 2022, 12, 837. [Google Scholar] [CrossRef] [PubMed]
- Hering, A.; Hansen, L.; Mok, T.C.; Chung, A.C.; Siebert, H.; Häger, S.; Lange, A.; Kuckertz, S.; Heldmann, S.; Shao, W.; et al. Learn2Reg: Comprehensive multi-task medical image registration challenge, dataset and evaluation in the era of deep learning. IEEE Trans. Med. Imaging 2022, 42, 697–712. [Google Scholar] [CrossRef] [PubMed]
- Varoquaux, G.; Cheplygina, V. Machine learning for medical imaging: Methodological failures and recommendations for the future. NPJ Digit. Med. 2022, 5, 48. [Google Scholar] [CrossRef]
- Tavolara, T.E.; Gurcan, M.N.; Niazi, M.K.K. Contrastive Multiple Instance Learning: An Unsupervised Framework for Learning Slide-Level Representations of Whole Slide Histopathology Images without Labels. Cancers 2022, 14, 5778. [Google Scholar] [CrossRef] [PubMed]
- Yao, H.; Hu, X.; Li, X. Enhancing pseudo label quality for semi-supervised domain-generalized medical image segmentation. In Proceedings of the Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI-22), Online, 22 February–1 March 2022; Volume 36, pp. 3099–3107. [Google Scholar]
- Shi, F.; Chen, B.; Cao, Q.; Wei, Y.; Zhou, Q.; Zhang, R.; Zhou, Y.; Yang, W.; Wang, X.; Fan, R.; et al. Semi-Supervised Deep Transfer Learning for Benign-Malignant Diagnosis of Pulmonary Nodules in Chest CT Images. IEEE Trans. Med. Imaging 2022, 41, 771–781. [Google Scholar] [CrossRef] [PubMed]
- Feng, Y.; Wang, Z.; Xu, X.; Wang, Y.; Fu, H.; Li, S.; Zhen, L.; Lei, X.; Cui, Y.; Ting, J.S.Z.; et al. Contrastive domain adaptation with consistency match for automated pneumonia diagnosis. Med. Image Anal. 2023, 83, 102664. [Google Scholar] [CrossRef] [PubMed]
- Fang, Y.; Wang, M.; Potter, G.G.; Liu, M. Unsupervised cross-domain functional MRI adaptation for automated major depressive disorder identification. Med. Image Anal. 2023, 84, 102707. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Xing, F.; El Fakhri, G.; Woo, J. Memory consistent unsupervised off-the-shelf model adaptation for source-relaxed medical image segmentation. Med. Image Anal. 2023, 83, 102641. [Google Scholar] [CrossRef]
- Hong, J.; Zhang, Y.D.; Chen, W. Source-free unsupervised domain adaptation for cross-modality abdominal multi-organ segmentation. Knowl.-Based Syst. 2022, 250, 109155. [Google Scholar] [CrossRef]
- Bateson, M.; Kervadec, H.; Dolz, J.; Lombaert, H.; Ayed, I.B. Source-free domain adaptation for image segmentation. Med. Image Anal. 2022, 82, 102617. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.E.; Cosa-Linan, A.; Santhanam, N.; Jannesari, M.; Maros, M.E.; Ganslandt, T. Transfer learning for medical image classification: A literature review. BMC Med. Imaging 2022, 22, 69. [Google Scholar] [CrossRef] [PubMed]
- Xue, C.; Yu, L.; Chen, P.; Dou, Q.; Heng, P.A. Robust medical image classification from noisy labeled data with global and local representation guided co-training. IEEE Trans. Med. Imaging 2022, 41, 1371–1382. [Google Scholar] [CrossRef] [PubMed]
- Placido, D.; Yuan, B.; Hjaltelin, J.X.; Zheng, C.; Haue, A.D.; Chmura, P.J.; Yuan, C.; Kim, J.; Umeton, R.; Antell, G.; et al. A deep learning algorithm to predict risk of pancreatic cancer from disease trajectories. Nat. Med. 2023, 29, 1113–1122. [Google Scholar] [CrossRef] [PubMed]
- Jiang, X.; Zhao, H.; Saldanha, O.L.; Nebelung, S.; Kuhl, C.; Amygdalos, I.; Lang, S.A.; Wu, X.; Meng, X.; Truhn, D.; et al. An MRI deep learning model predicts outcome in rectal cancer. Radiology 2023, 307, e222223. [Google Scholar] [CrossRef] [PubMed]
- Rehman, M.U.; Akhtar, S.; Zakwan, M.; Mahmood, M.H. Novel architecture with selected feature vector for effective classification of mitotic and non-mitotic cells in breast cancer histology images. Biomed. Signal Process. Control 2022, 71, 103212. [Google Scholar] [CrossRef]
- Huo, X.; Sun, G.; Tian, S.; Wang, Y.; Yu, L.; Long, J.; Zhang, W.; Li, A. HiFuse: Hierarchical multi-scale feature fusion network for medical image classification. Biomed. Signal Process. Control 2024, 87, 105534. [Google Scholar] [CrossRef]
- Zhang, S.; Miao, Y.; Chen, J.; Zhang, X.; Han, L.; Ran, D.; Huang, Z.; Pei, N.; Liu, H.; An, C. Twist-Net: A multi-modality transfer learning network with the hybrid bilateral encoder for hypopharyngeal cancer segmentation. Comput. Biol. Med. 2023, 154, 106555. [Google Scholar] [CrossRef] [PubMed]
- Wen, L.; Xiao, J.; Zeng, J.; Zu, C.; Wu, X.; Zhou, J.; Peng, X.; Wang, Y. Multi-level progressive transfer learning for cervical cancer dose prediction. Pattern Recognit. 2023, 141, 109606. [Google Scholar] [CrossRef]
- Wang, P.; Li, P.; Li, Y.; Xu, J.; Jiang, M. Classification of histopathological whole slide images based on multiple weighted semi-supervised domain adaptation. Biomed. Signal Process. Control 2022, 73, 103400. [Google Scholar] [CrossRef]
- Hu, J.; Zhong, H.; Yang, F.; Gong, S.; Wu, G.; Yan, J. Learning Unbiased Transferability for Domain Adaptation by Uncertainty Modeling. In Computer Vision—ECCV 2022: Proceedings of the 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 223–241. [Google Scholar]
- Pei, J.; Jiang, Z.; Men, A.; Chen, L.; Liu, Y.; Chen, Q. Uncertainty-induced transferability representation for source-free unsupervised domain adaptation. IEEE Trans. Image Process. 2023, 32, 2033–2048. [Google Scholar] [CrossRef] [PubMed]
- Shamsi, A.; Asgharnezhad, H.; Jokandan, S.S.; Khosravi, A.; Kebria, P.M.; Nahavandi, D.; Nahavandi, S.; Srinivasan, D. An uncertainty-aware transfer learning-based framework for COVID-19 diagnosis. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 1408–1417. [Google Scholar] [CrossRef]
- Ebadi, N.; Li, R.; Das, A.; Roy, A.; Nikos, P.; Najafirad, P. CBCT-guided adaptive radiotherapy using self-supervised sequential domain adaptation with uncertainty estimation. Med. Image Anal. 2023, 86, 102800. [Google Scholar] [CrossRef] [PubMed]
- Tierney, L.; Kadane, J.B. Accurate approximations for posterior moments and marginal densities. J. Am. Stat. Assoc. 1986, 81, 82–86. [Google Scholar] [CrossRef]
- NCT-CRC-HE-100K Dataset. Available online: https://zenodo.org (accessed on 31 January 2024).
- Veeling, B.S.; Linmans, J.; Winkens, J.; Cohen, T.; Welling, M. Rotation equivariant CNNs for digital pathology. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2018: Proceedings of the 21st International Conference, Granada, Spain, 16–20 September 2018; Proceedings, Part II 11; Springer: Cham, Switzerland, 2018; pp. 210–218. [Google Scholar]
- Borkowski, A.A.; Bui, M.M.; Thomas, L.B.; Wilson, C.P.; DeLand, L.A.; Mastorides, S.M. Lung and colon cancer histopathological image dataset (lc25000). arXiv 2019, arXiv:1912.12142. [Google Scholar]
- Bejnordi, B.E.; Veta, M.; Van Diest, P.J.; Van Ginneken, B.; Karssemeijer, N.; Litjens, G.; Van Der Laak, J.A.; Hermsen, M.; Manson, Q.F.; Balkenhol, M.; et al. Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer. JAMA 2017, 318, 2199–2210. [Google Scholar] [CrossRef] [PubMed]
- Gidaris, S.; Singh, P.; Komodakis, N. Unsupervised representation learning by predicting image rotations. In Proceedings of the Sixth International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–16. [Google Scholar]
- Caron, M.; Bojanowski, P.; Joulin, A.; Douze, M. Deep clustering for unsupervised learning of visual features. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 132–149. [Google Scholar]
- Li, J.; Liu, J.; Yue, H.; Cheng, J.; Kuang, H.; Bai, H.; Wang, Y.; Wang, J. DARC: Deep adaptive regularized clustering for histopathological image classification. Med. Image Anal. 2022, 80, 102521. [Google Scholar] [CrossRef] [PubMed]
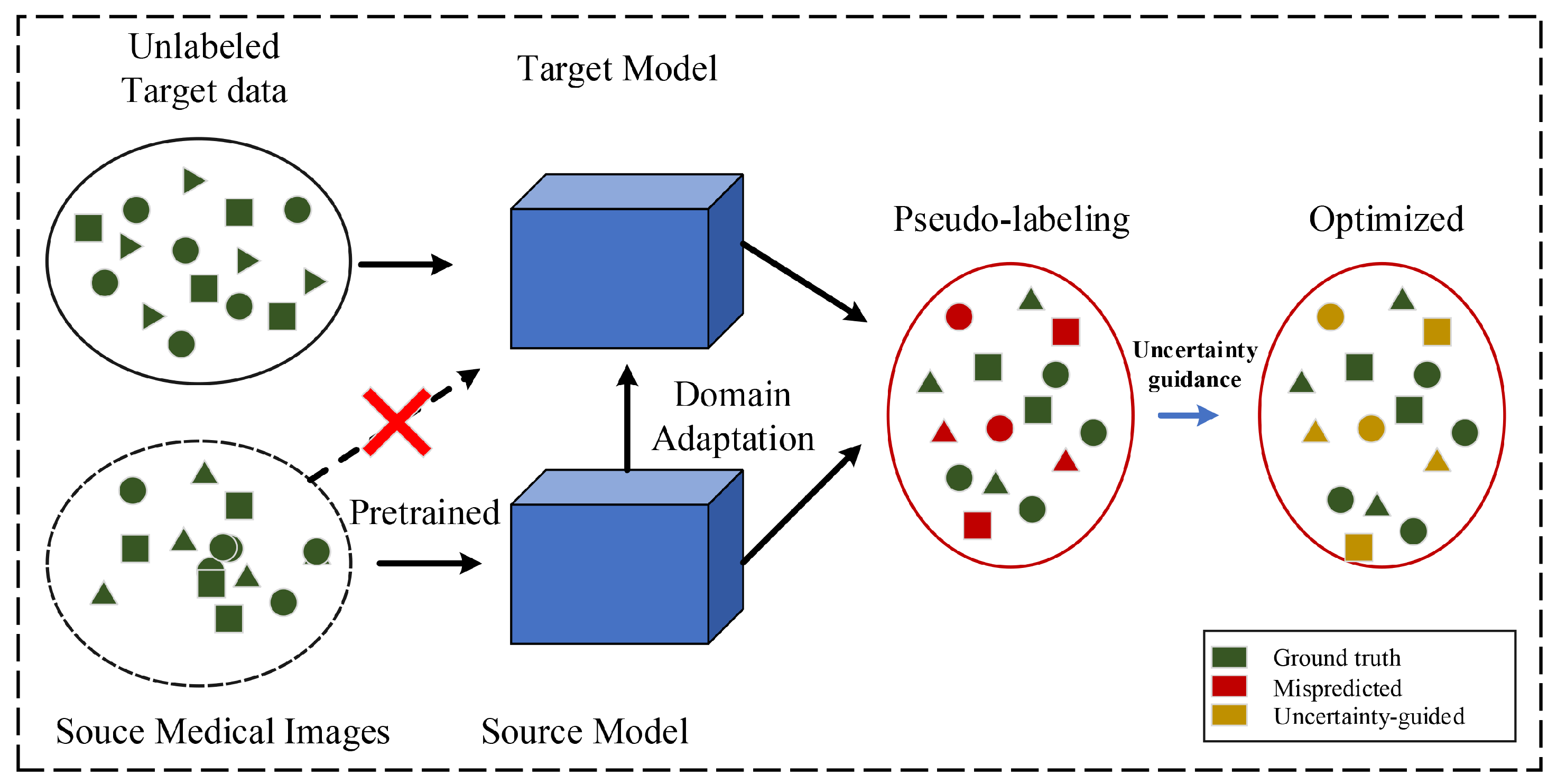
Figure 1.
The workflow of the proposed UCDA.

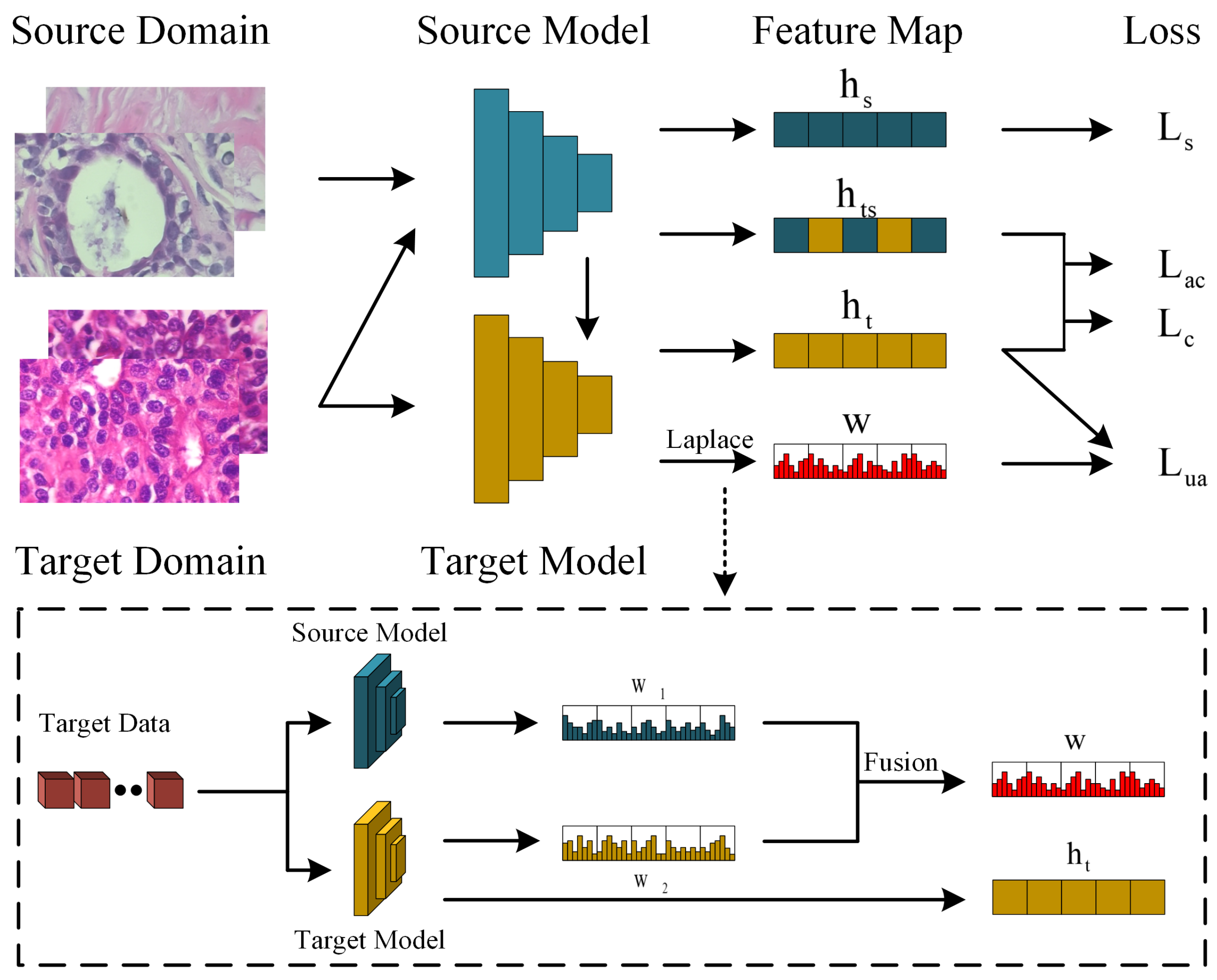
Figure 2.
The proposed architecture of the uncertainty-guided asymmetric consistency domain adaptation. Note that the red box displays the entire model training flowchart. The process begins with the source domain where histopathological images undergo initial feature extraction through a source model pre-trained from (Step 1). To address the challenges posed by data privacy and the unavailability of large-scale annotated datasets, the Uncertainty-guided Source-free Transfer Learning (USTL) component operates to map the feature space of the source model to the target domain without requiring access to the source data, which can quantifies and mitigates network uncertainties, generating high-quality pseudo-labels for target data (Step 2). Concurrently, the Asymmetric Consistency Learning (ACL) component quantifies and utilizes the symmetries and asymmetries between the source and target domains, facilitating the preservation of crucial inter-domain differences.
Figure 2.
The proposed architecture of the uncertainty-guided asymmetric consistency domain adaptation. Note that the red box displays the entire model training flowchart. The process begins with the source domain where histopathological images undergo initial feature extraction through a source model pre-trained from (Step 1). To address the challenges posed by data privacy and the unavailability of large-scale annotated datasets, the Uncertainty-guided Source-free Transfer Learning (USTL) component operates to map the feature space of the source model to the target domain without requiring access to the source data, which can quantifies and mitigates network uncertainties, generating high-quality pseudo-labels for target data (Step 2). Concurrently, the Asymmetric Consistency Learning (ACL) component quantifies and utilizes the symmetries and asymmetries between the source and target domains, facilitating the preservation of crucial inter-domain differences.

Figure 3.
The ROC curves of our UCDA model on PCam and LC25000 datasets, where only 1% of the data were labeled.
Figure 3.
The ROC curves of our UCDA model on PCam and LC25000 datasets, where only 1% of the data were labeled.

Figure 4.
(a,b) are the respective feature visualizations of the UCDA model on PCam and LC25000 datasets with 1% labeled data.
Figure 4.
(a,b) are the respective feature visualizations of the UCDA model on PCam and LC25000 datasets with 1% labeled data.

Figure 5.
Variation in accuracy obtained using different backbone networks on the Pcam dataset.

Figure 6.
Performance change in UCDA after removing uncertainty loss.

Figure 7.
The parameter analysis for asymmetric consistency loss , uncertainty-guided adaptation loss , and the contrast loss in Equation (15), which is conducted on PCam with 1% labeled data.
Figure 7.
The parameter analysis for asymmetric consistency loss , uncertainty-guided adaptation loss , and the contrast loss in Equation (15), which is conducted on PCam with 1% labeled data.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Comparing performance on PCam and LC25000 datasets with different labeled data ratios.
| Labeled Data | Methods | PCam | LC25000 | NCT-CRC-HE-100K | |||
|---|---|---|---|---|---|---|---|
| Accuracy | F1-Score | Accuracy | F1-Score | Accuracy | F1-Score | ||
| 1% | Rotation [34] | 80.81 | 80.68 | 88.27 | 88.25 | 88.27 | 88.01 |
| DeepCluster [35] | 84.52 | 84.36 | 87.26 | 87.32 | 91.94 | 91.85 | |
| DARC [36] | 85.50 | 85.52 | 90.76 | 90.81 | 92.62 | 92.63 | |
| UCDA (Ours) | 86.83 | 86.60 | 90.91 | 90.89 | 94.65 | 94.72 | |
| 10% | Rotation [34] | 83.95 | 83.64 | 93.65 | 93.45 | 94.59 | 94.46 |
| DeepCluster [35] | 87.56 | 87.50 | 97.76 | 97.66 | 97.57 | 97.65 | |
| DARC [36] | 87.77 | 87.7 | 97.95 | 97.97 | 98.57 | 98.50 | |
| UCDA (Ours) | 88.65 | 88.68 | 96.59 | 96.52 | 99.62 | 99.52 | |
| 50% | Rotation [34] | 86.03 | 86.12 | 97.61 | 97.66 | 97.85 | 97.89 |
| DeepCluster [35] | 89.19 | 89.22 | 99.59 | 99.54 | 98.47 | 98.45 | |
| DARC [36] | 88.75 | 88.7 | 99.88 | 99.81 | 99.57 | 99.53 | |
| UCDA (Ours) | 89.78 | 89.63 | 96.36 | 96.30 | 99.65 | 99.60 | |
Note: The bold content is the highest result in comparison.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Yu, C.; Pei, H. Uncertainty-Guided Asymmetric Consistency Domain Adaptation for Histopathological Image Classification. Appl. Sci. 2024, 14, 2900. https://doi.org/10.3390/app14072900
AMA Style
Yu C, Pei H. Uncertainty-Guided Asymmetric Consistency Domain Adaptation for Histopathological Image Classification. Applied Sciences. 2024; 14(7):2900. https://doi.org/10.3390/app14072900
Chicago/Turabian StyleYu, Chenglin, and Hailong Pei. 2024. "Uncertainty-Guided Asymmetric Consistency Domain Adaptation for Histopathological Image Classification" Applied Sciences 14, no. 7: 2900. https://doi.org/10.3390/app14072900
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.